Local LLMs for natural language processing on sensitive data
Use Ollama and Python to run Mistral locally for sentiment analysis and other NLP tasks.


Intro
In a previous post I showed you how you can do sentiment analysis using remote AI models with SQL in BigQuery.
But if you're trying to do natural language processing then you're probably working with PII and other sensitive data so you need to be careful processing your data in the cloud.
In this post I'll show you how you can do NLP locally using pre-trained LLMs like Mistral 7B, LLama 2, or any other open source model that you can run on your machine. We'll evaluate the results produced locally against results generated by cloud services like Google's Natural Language API and Gemini Pro.
First, the results
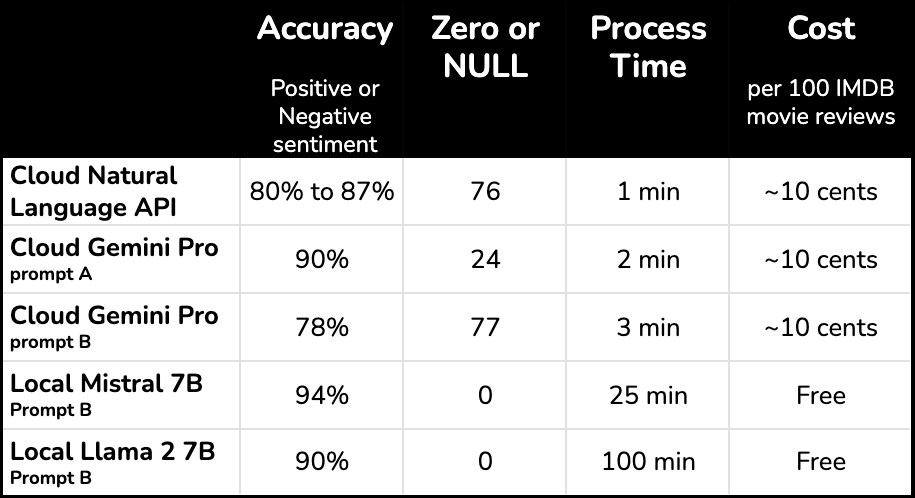
Mistral 7B running on my machine proved to be the most accurate of all models tested. It correctly inferred the sentiment of a sample of movie reviews 94% of the time.
The results suggest that local LLMs can be just as accurate (and much cheaper) than cloud services for sentiment analysis and other NLP tasks. But running these models on your machine can take a very long time – 20 minutes or longer to process 500 entries.
Heads up
My evaluation method is quick and dirty. See the Evaluation section for detail.
The cloud services returned zeros and nulls. NULLs returned by the natural langauge API represent neutral sentiment on a -1 to 1 scale (so I'm told). But NULLs returned by Gemini are equivalent to zero signal since the prompt requested that all reviews get scored on a scale of 1 to 10.
These local models are "vanilla". They are what you get out of the box when you install mistral and llama2 locally through Ollama. They are 4-bit quantized gguf files. I did no fine tuning. All the docs and subreddits say fine tuning is necessary to get maximum accuracy out of an LLM. Also, I didn't experiment with BERT or other open source models which are purpose-built for NLP tasks like this, and which might run a lot faster on your machine. (These might be posts for another time.)
Local LLM Requirements
To run AI models locally for NLP you'll need...
A Mac with an M1 or M2 processor. You can also run these models on Windows machines with sufficient processing power, but you won't find those instructions here.
Basic Python skills. You could just copy / paste the code and run it, but that will be easier if you've previously opened Python on your machine. Python environment setup is the hardest part of this process.
Example: A movie review
The Rainmaker

The reviewer gave this review 2 stars.
Sentiment scores

All models tested did a good job inferring the sentiment of this movie review.
In the final row of the result you can see where I started to play around with text classification using Mistral 7B. There is lots of potential to use local LLMs for ANY natural language task, such as extracting entities or themes in free response, which is an important step in root cause analysis.
The code
This Python script iterates through a CSV column, sends each row to a local LLM (Mistral 7B in this case), and stores the response in a new column.
import pandas, ollama, time
from numpy import nan
## read in the csv and turn it into a pandas dataframe
df = pandas.read_csv('/your/csv/path/csv_name.csv')
dfsample = df.head(5)
start = time.time()
prompt =
"""What is the sentiment of this movie review?
Respond with a value between 1 and 10, where 1 is hate and 10 is love.
Return a result in this json schema: "{"sentiment":{"type":"int"}, "explanation":{"type":"text"}}"
This is the movie review: """
def llm(row):
response = ollama.chat(model='mistral', messages=[{'role': 'user',
'content': prompt + row['text_content']}])
return response['message']['content']
dfsample['mistral response'] = df.apply(lambda row: llm(row), axis=1)
end = time.time()
print ('Elapsed time (seconds): ', int(end - start))
## extract integer score from the dirty response
dfsample['mistral sentiment score'] = dfsample['mistral response'].str.extract('(\d+)'
).astype(float)
dfsample.head(5)How the code works
- Reads in a CSV and saves it as a pandas dataframe
- Stores a prompt as
prompt, an argument that's expected by Mistral, LLama 2 and some of the other open source models available through Ollama. In this case our prompt asks for a sentiment score between 1 and 10, plus an explanation for the score, and asks to store it in a json-like format. Through some trial and error I've found this is a good way to force a response that's easily parsed into a numeric. - Concatenates the prompt with the movie review and sends it through the Ollama function
chatto the model 7B Mistral. - Applies the model response to the dataframe as a new column called
mistral response. - Times the process and prints the duration and also the first 5 rows of the full result so you can glance at a few responses.
Running the code & getting results
First, install Ollama to run LLMs locally. This was so easy. Even if you do nothing else described in this post, you should do this so you can prompt a local LLM through your terminal. Or even ask it to summarize an entire CSV:
$ ollama run llama2 "$(cat /path/to/your/file.csv)" please summarize this dataDownload models: Mistral 7B and Llama2 through the terminal.
$ ollama run mistralImport the movie reviews CSV into Jupyter Lab or another local Python environment and convert it to a pandas dataframe. This 471-row CSV was previously generated in BigQuery, and it includes free text movie reviews, user submitted scores on a scale of 1-10, plus sentiment scores as determined by the cloud services NLP API and Gemini Pro
Write a prompt to instruct the LLMs to do sentiment analysis on movie reviews. This takes a few tries to get the prompt right, so test a prompt on a smaller sample until you get a response that seems to give a good result.
Run a python function to iterate through the dataset, sending the prompt concatenated with the movie review to the local LLM and storing the response in a new column. Running 500-rows through the LLM can take 20 minutes or longer.
Do it again for each local LLM.
Clean the result. We asked the model to return a score on a scale of 1 to 10, but many responses are dirty. Use regex (like I did in the code above) or a method of your choice to generate a clean column on a scale of 1 to 10.
Label each response as positive or negative. At this point all results are on a scale of 1 to 10 except the result generated with Google's Natural Language API which gives a response on a scale of -1 to 1. We need to get these result on the same scale as the ground truth provided by the movie reviewer. The IMDB movie reviews dataset ONLY includes positive and negative reviews. The data scientists who created it (Andrew Ng, Andrew Maas, et al) excluded "neutral" 5 and 6 reviews. They labeled 1-4 as negative and 7-10 as positive.
Here's the distribution of sentiment scores before I converted the scores to positive and negative.
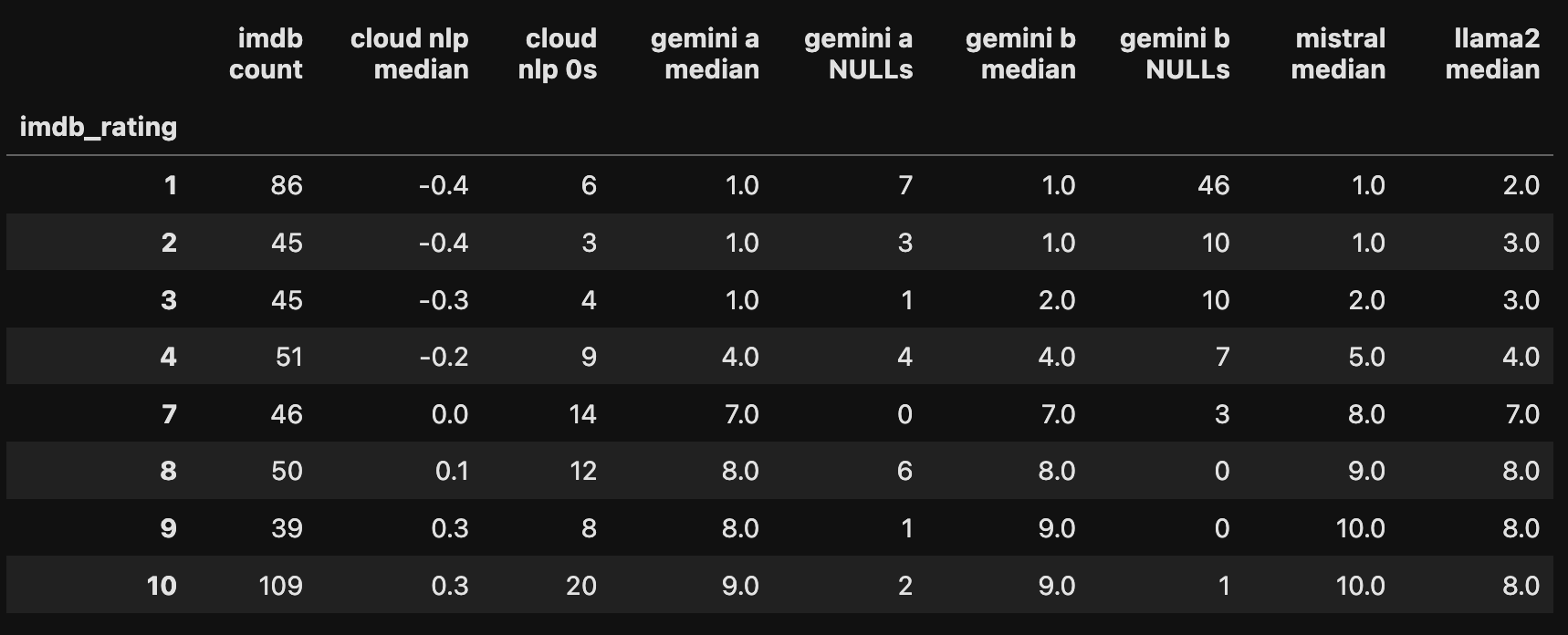
Luckily, the sentiment scores line up well with the IMDB scores. We don't need to grade the scores on a curve. For IMDB (ground truth), Gemini Pro, Mistral and Llama2, I assigned negative labels to scores under 7, and positive labels to scores of 7-10.
For the Natural Language API results I wasn't sure what to do with the zeroes, so I tried two methods, assigning zeroes to positive (a) and negative (b).
Now we've got a complete labeled dataset and we're ready to compare all models vs. ground truth.
Evaluation & conclusion

Mistral 7B was the winner, though it took about 20 minutes to generate the result for 471 movie reviews.
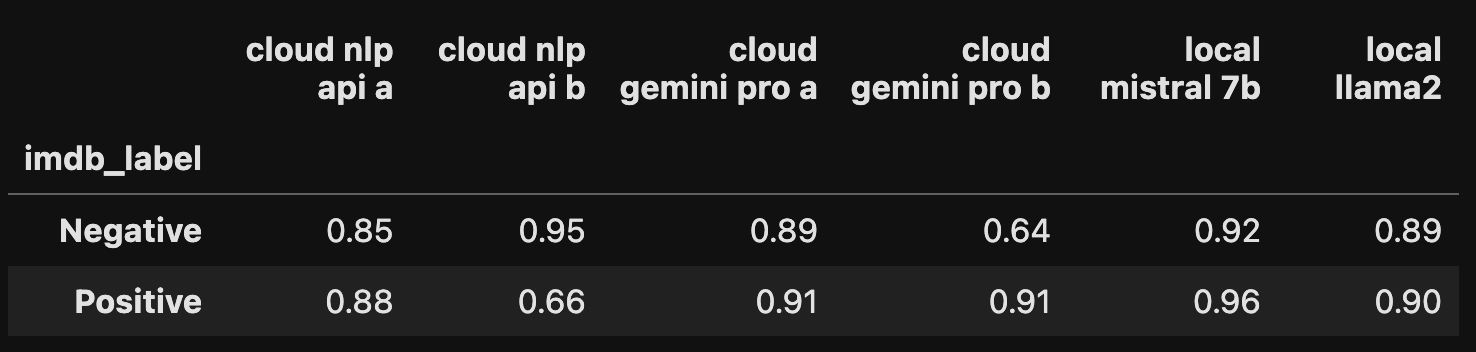
I suspect we can get increased accuracy from all the models with improved prompting and additional steps like fine tuning. And there's gotta be a trick to coax better results and fewer NULLs out of Google's cloud services. If you know how, please let me know.
Either way, you might consider pivoting if you are in the business of selling NLP services because it's not so hard today to do the hard work pretty well, though slowly, on your own machine.
Have questions or anything to add? Leave a comment or say hi.
Further reading...
 Sam Brand
Sam Brand Sam Brand
Sam Brand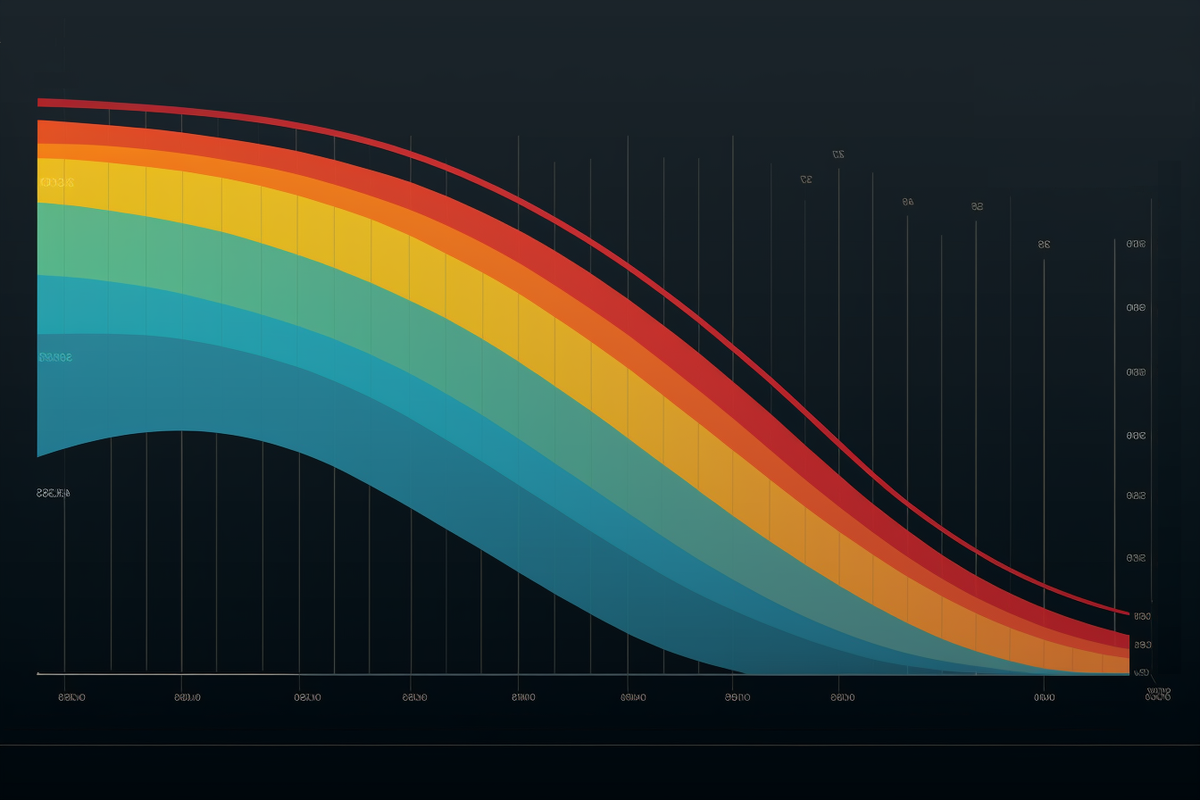 Sam Brand
Sam Brand